Agentic AI is one of those phrases that sounds powerful enough to explain everything and vague enough to explain nothing. In demos, it usually means "the AI did more than answer a question." In production, that definition is not good enough.
The useful definition is narrower: agentic AI is a system where a model can decide how to pursue a goal, use tools, observe the results, and continue or stop based on what happened. Google's agent whitepaper describes an agent as a program that extends a generative model with reasoning, logic, and access to external information, while OpenAI describes agents as systems that independently accomplish tasks on behalf of users.
That sounds simple until the agent has permission to touch real systems. The moment an AI can query a database, send a message, update a ticket, create a pull request, or call an API, the problem stops being only "how smart is the model?" and becomes "how safely does the whole loop behave?"
The shortest useful definition
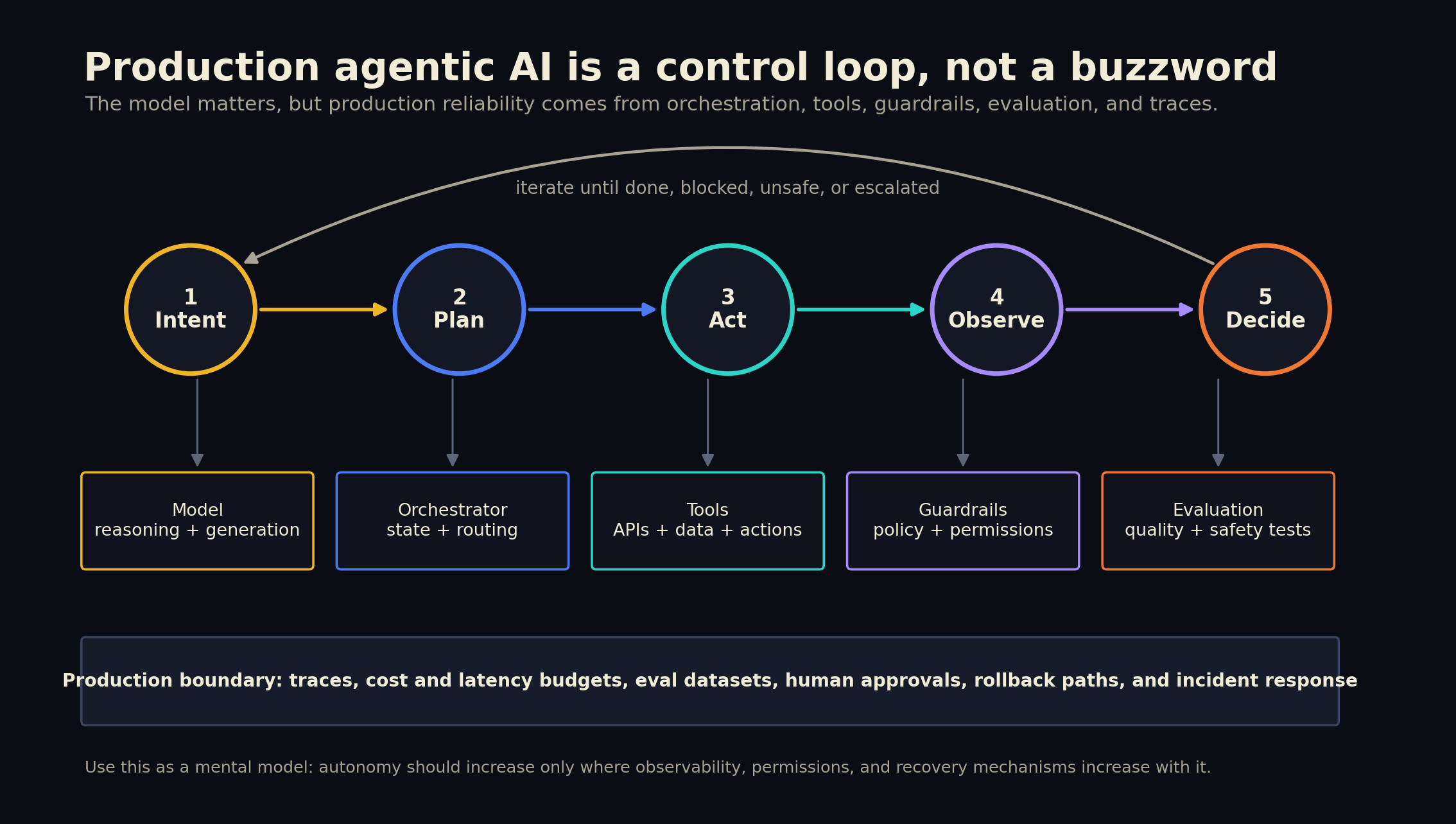
Agentic AI in production is not "a chatbot with a cooler name." It is a control loop:
- Intent: The user or system gives the agent a goal.
- Plan: The agent decides a path, sometimes decomposing the goal into smaller steps.
- Act: The agent calls tools, retrieves data, writes files, invokes APIs, or asks another agent for help.
- Observe: The agent reads tool results, errors, constraints, and environmental feedback.
- Decide: The agent continues, stops, escalates, retries, or asks for human approval.
That loop is what separates an agent from a single prompt-response interaction. Anthropic draws a useful distinction here: workflows are LLM-and-tool systems orchestrated through predefined code paths, while agents dynamically direct their own process and tool usage.
This distinction matters because "more agentic" is not automatically better. If the path is known, predictable, and easy to encode, a workflow is often the better engineering choice. Anthropic explicitly recommends using the simplest solution that works, because agents trade predictability, latency, and cost for flexibility.
The production shift: from output quality to system behavior
The buzzword version of agentic AI focuses on autonomy. The production version focuses on boundaries.
A prototype agent asks, "Can the model complete the task?" A production agent asks:
- Can it choose the right tool?
- Can it recover when the tool fails?
- Can it tell when it does not have enough information?
- Can it stay within permission boundaries?
- Can the team replay what happened after a bad outcome?
- Can the system be evaluated before and after deployment?
Microsoft's agent architecture guidance describes a maturity ladder that starts with direct model calls, moves to a single agent with tools, and only then moves to multi-agent orchestration when the added coordination cost is justified. That is a very practical way to think about it: the default should not be "make everything multi-agent." The default should be "add agency only where fixed paths break down."
A production agent is really five systems wearing one name
When people say "agent," they often point to the model. But in production, the model is only one component.
OpenAI's Agents SDK documentation reflects this production shape: agents are LLMs equipped with instructions and tools, while the runtime handles tool invocation, turns, handoffs, guardrails, and tracing. The important point is not that every team must use a specific SDK. The important point is that serious agent systems converge on the same ingredients: tools, state, guardrails, handoffs, and traces.
Why tool use is the real inflection point
Tool use is where agentic AI becomes useful and dangerous at the same time.
A model that only writes text can be wrong. A model that can use tools can be wrong and take action. That action might be harmless, like searching documentation, or high-impact, like sending a customer email, changing production configuration, or modifying a database record.
This is why permissions matter more than personality. A production agent should not receive broad access because the demo looked good. It should receive the smallest useful set of tools, the narrowest useful permissions, and clear rules for when a human must approve the next step.
OWASP's LLM risk guidance is especially relevant here. Prompt injection can happen when user input or external content alters model behavior in unintended ways, including indirect prompt injection from websites or files the model reads. That risk becomes more serious when the model can call tools, because malicious or untrusted content can try to influence what the agent does next.
The trap: confusing autonomy with reliability
The most common mistake is to assume that an agent is more advanced because it has more freedom. In production, freedom without observability is just hidden risk.
A reliable agent does not need unlimited autonomy. It needs calibrated autonomy. It should know when to continue, when to stop, when to ask for help, and when a task is outside its boundary.
This is the same lesson software teams learn with any automation. A cron job that silently does the wrong thing is worse than a manual process. A deployment script without rollback is fragile. An AI agent without traceability, permissions, and evals is the same pattern in a newer wrapper.
Observability is not optional
Traditional software debugging often starts with logs and stack traces. Agent debugging starts with trajectories: what the model saw, what it decided, which tools it called, what came back, and why the next step followed.
LangChain's agent observability guidance argues that agent behavior often emerges at runtime, so traces become the source of truth for understanding why an agent behaved a certain way. That makes sense because agent failures are not always code failures. Sometimes the code works exactly as written, but the model chooses the wrong tool, passes the wrong argument, over-trusts retrieved context, or keeps looping after it should stop.
Good traces should answer practical questions:
- What was the original goal?
- What context did the model receive?
- Which tools were available?
- Which tool did it choose and why?
- What arguments did it pass?
- What did the tool return?
- Which guardrails ran?
- Where did cost, latency, or quality degrade?
Without those answers, every production issue becomes a debate about vibes.
Evaluation has to move beyond "the final answer looked good"
Agent evaluation is harder than chatbot evaluation because the final answer is only one part of the behavior. A bad agent can produce a good-looking final answer after taking the wrong path, leaking information into a tool call, ignoring a policy, or wasting ten times the necessary cost.
Production evaluation should measure the path as well as the result:
- Task success: Did the agent actually complete the user's goal?
- Tool choice: Did it call the right tool at the right time?
- Tool arguments: Did it pass valid, minimal, safe parameters?
- Grounding: Did it use retrieved or external information correctly?
- Policy adherence: Did it respect permissions, privacy, and escalation rules?
- Efficiency: Did it complete the task within acceptable latency and cost?
- Recovery: Did it handle errors, missing data, and ambiguity gracefully?
LangChain's 2025 State of Agent Engineering survey reported that observability had higher adoption than evals among surveyed teams, with observability at 89% and eval adoption at 52%. The direction is believable: teams often start by tracing what happened, then turn those traces into regression tests and evaluation datasets.
Multi-agent systems are not automatically more mature
Multi-agent systems are attractive because they map to how humans organize work: one agent researches, another writes, another reviews, another executes. But production systems pay for every handoff.
More agents can mean: more coordination overhead, more latency, more state to manage, more places for context to drift, more difficult debugging, and more ambiguous responsibility when something fails.
The right bar for multi-agent architecture: use it when specialization genuinely earns its keep, not because the diagram looks more impressive.
A practical maturity model
If building toward production, the progression should usually look like this:
This model keeps the engineering conversation honest. "Agentic" should not be a binary label. It should be a question of how much decision-making the system is allowed to own, and what controls increase as that autonomy increases.
The production checklist
Before calling something a production agent, ask whether it has these basics:
NIST's AI Risk Management Framework is useful as a broader governance lens because it frames AI risk management around building trustworthy systems and incorporating trustworthiness considerations into design, development, use, and evaluation. For agents, that means reliability is not just a model benchmark. It is an operating discipline.
What this means for builders
The best production agents will probably feel less dramatic than the demos. They will be narrower, more instrumented, more permissioned, and more boring in exactly the right ways.
That is not a downgrade. That is how useful systems survive contact with real users.
The real promise of agentic AI is not that software suddenly becomes autonomous everywhere. The promise is that certain workflows can become adaptive where rigid automation used to break: support triage, internal research, codebase navigation, data analysis, operational runbooks, content operations, and domain-specific assistants.
The engineering challenge is to put autonomy in the right places. Let the model handle ambiguity, planning, and language. Let code handle invariants, permissions, routing, persistence, and irreversible actions. Let humans approve the steps where judgment, accountability, or risk still matters.
The line I would draw
If an AI system only answers, it is a model interface.
If it follows a fixed sequence, it is a workflow.
If it can choose tools, inspect results, update its plan, and continue toward a goal, it is agentic.
If it can do that with permissions, traces, evals, cost controls, human approvals, and recovery paths, it is production agentic AI.
That last version is the one worth building.