Homeowner Loss
History Prediction
A production-style MLOps system for homeowner loss prediction that turns a manual actuarial modeling workflow into an automated, auditable, human-in-the-loop AI pipeline. Built with Grange Insurance × University of Toledo.
From notebook workflow to governed, continuously operating AI platform
Homeowner Loss History Prediction was a senior design project developed in partnership with Grange Insurance to modernize how homeowner risk and pure premium predictions are modeled, validated, monitored, and updated. Instead of treating machine learning as a one-time notebook workflow, the project reframed risk modeling as a continuously operating MLOps system.
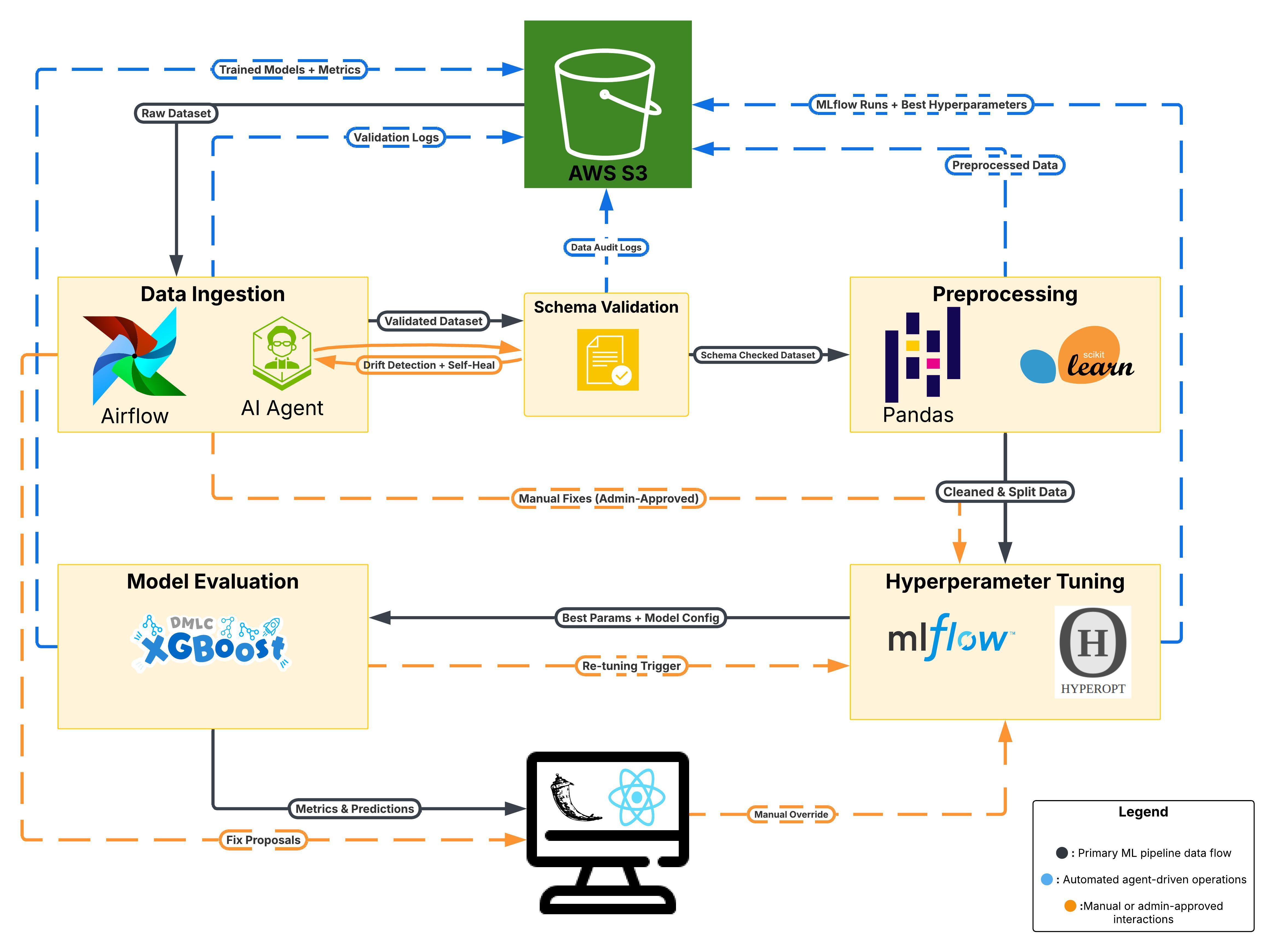
The system automates the full lifecycle: raw data ingestion, schema validation, preprocessing, feature engineering, drift detection, model training, hyperparameter tuning, model evaluation, experiment tracking, monitoring, alerting, and human-approved deployment.
The key contribution was not just improving model accuracy. The bigger engineering contribution was building a governed ML operating system around the model: every dataset, schema, model run, drift event, metric, and manual decision can be tracked, reviewed, and reproduced.
Risk patterns shift faster than manual modeling can adapt
Insurance companies need accurate homeowner risk models for pricing, underwriting, and financial stability. However, many modeling workflows are still too manual for modern claim volatility — claim volatility, inflation, weather events, and regional property-risk trends all create windows where stale models make pricing decisions.
Model updates required manual data pulls, notebook-based preprocessing, and repeated rebuilds — consuming actuarial time that should be focused on interpretation.
Data schema changes could silently break downstream training with no validation layer catching type mismatches or missing columns before they corrupted model runs.
Model drift was difficult to detect early without automated monitoring. Stale models could price risk for weeks before a human noticed performance degradation.
Without tracking, experiments and model versions were hard to reproduce. There was no audit trail for when a model was promoted, what data it saw, or who approved it.
Business stakeholders and actuaries needed explainability, not just predictions. A black-box model creates regulatory and trust problems in insurance.
High-stakes insurance decisions require human oversight, auditability, and the ability to roll back. A notebook-only workflow provides none of these guarantees.
Modular MLOps pipeline — end-to-end
The architecture was built as a modular MLOps workflow instead of a single monolithic script. Each stage is independently testable, observable, and replaceable.
Purpose-selected tools for each layer
Why XGBoost — and what it took to govern it
XGBoost was chosen because it offered the best balance between predictive performance, explainability, speed, and insurance-industry practicality — not just the highest raw metric.
Hyperopt with Bayesian optimization searched across learning rate, max depth, subsample, colsample, and regularization parameters. Every tuning run was tracked in MLflow with the associated training dataset snapshot, enabling reproducible comparison across experiments and preventing the common problem of "which run was the best one?"
Strong predictive performance and meaningful automation gains
The real value: automation with governance
The 75% reduction didn't happen because humans were removed from the workflow. It happened because the system moved humans to the right point in the loop — intervening only where judgment matters, not at every routine validation step.
It prevents silent failures from cascading into bad model training. Data schema changes can break downstream training without any visible error until the model produces wrong outputs.
Prometheus-style metrics and alerting helped expose system-level problems earlier. A model that works but can't be observed isn't production-ready.
Actuary involvement and manual approval gates made the automation more credible to stakeholders, not less. Governance isn't overhead — it's what makes automation trustworthy.
MLflow made it easier to compare runs, preserve model lineage, and reproduce results. Without it, the question of "which configuration produced this model?" has no good answer.
Automatic retraining is powerful, but unsafe without approval, rollback, and explanation. Self-healing workflows need human checkpoints before they touch production.
Where the platform goes next
Event-driven architecture for faster scoring and streaming updates rather than batch ingestion cycles.
Separate model tracks for water, wind/hail, fire, and property-loss categories rather than a single monolithic model.
Managed training, hosted endpoints, model monitoring, and registry workflows through SageMaker to reduce operational overhead.
AIF360 or Fairlearn integration to continuously audit model outputs for demographic fairness and flag bias drift.
Secure sandbox where AI agents can propose drift fixes before human approval — explanation tracing included.
Actual-vs-predicted premium overlays and cohort-level variance views to give actuaries richer inspection of model behavior by risk segment.
Read the full technical report
The final report covers methodology, feature engineering details, model evaluation, pipeline architecture diagrams, and governance framework in full.